*七、Spark-Standalone-HA模式*
注:此处因为先前配置时的zookeeper版本和spark版本不太兼容,导致此模式有故障,需要重新下载配置新的版本的zookeeper。配置之前需要删除三台主机的旧版zookeeper以及对应的软连接。
在node1节点上重新进行前面配置的zookerper操作
\1. 上传apache-zookeeper-3.7.0-bin.tar.gz到/export/server/目录下并解压文件
1 | cd /export/server/ |
\2. 在/export/server/目录下创建软连接
1 | cd /export/server/ |
\3. 进入/export/server/zookeeper/conf/将zoo_sample.cfg文件复制为新文件 zoo.cfg
\4. 接上步给zoo.cfg 添加内容
\5. 进入/export/server/zookeeper/zkdatas 目录在此目录下创建 myid 文件,将1写入进去
\6. 将node1节点中 /export/server/zookeeper-3.7.0 路径下内容分发给node2和node3
\7. 分发完后,分别在node2和node3上创建软连接
\8. 将node2和node3的/export/server/zookeeper/zkdatas/文件夹
下的myid中的内容分别改为2和3
配置环境变量:
因先前配置 zookeeper 时候创建过软连接且以 ’zookeeper‘ 为路径,所以不用配置环境变量,此处也是创建软连接的方便之处.
1 | cd /export/server/spark/conf |
1 | vim spark-env.sh |
删除: SPARK_MASTER_HOST=node1
在文末添加内容
1 | SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER - |
\9. 分发spark-env.sh到node2和node3上
1 | scp spark-env.sh node2:/export/server/spark/conf/ |
\10. 启动之前确保 Zookeeper 和 HDFS 均已经启动
启动集群:
# 在node1上 启动一个master 和全部worker
1 | sbin/start-all.sh |
# 注意, 下面命令在node2上执行
1 | sbin/start-master.sh |
# 在node2上启动一个备用的master进程
#将node1的master kill掉,查看node2的WebUI界面
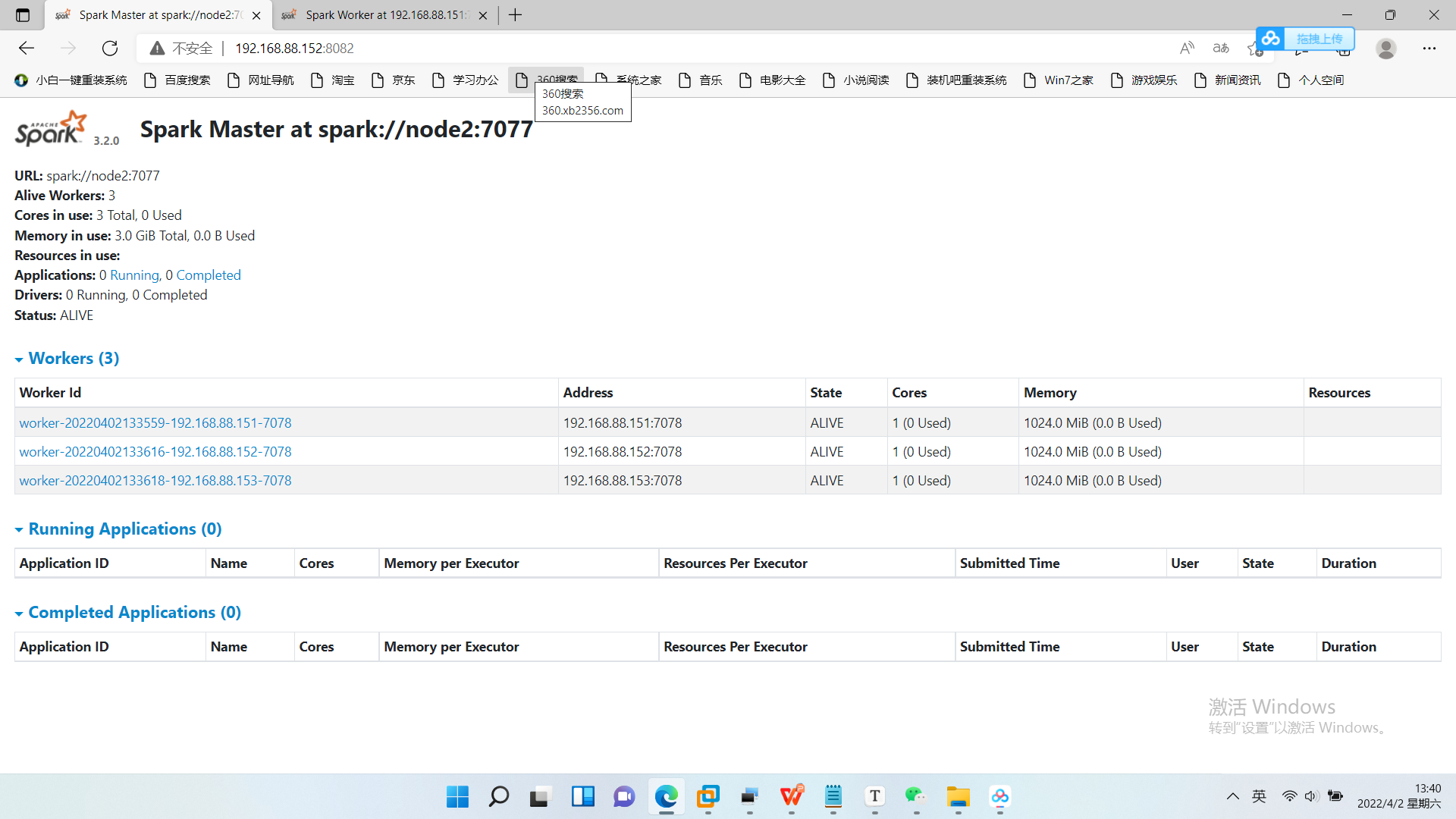
*八、Spark-yarn模式*
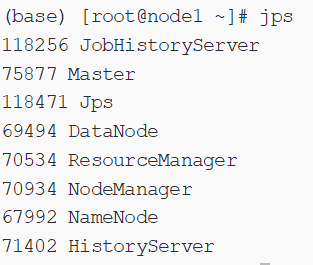
1、启动yarn的历史服务器,jps看进程
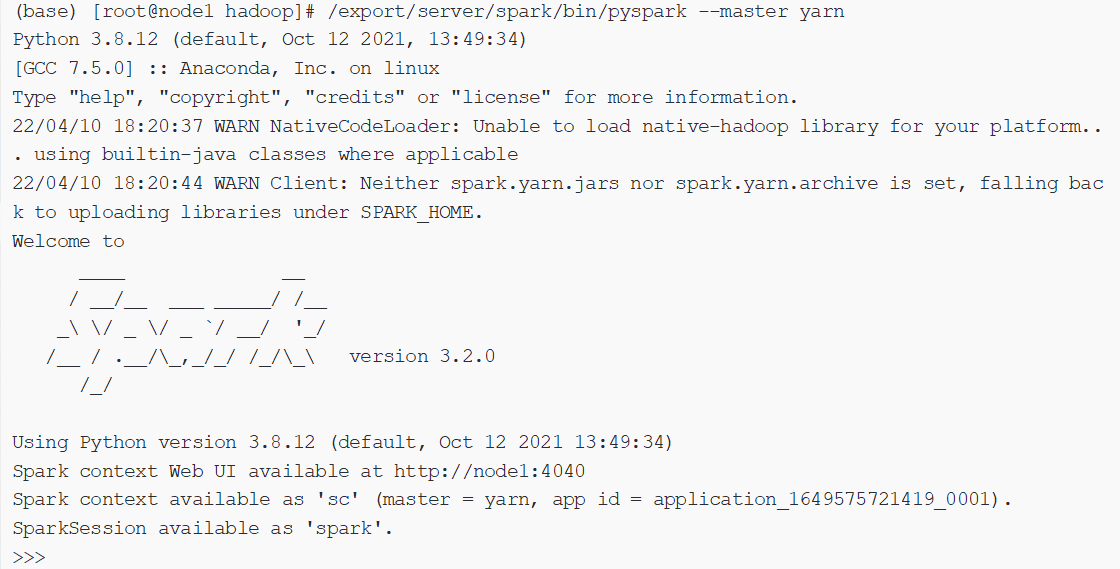
2、在yarn上启动pyspark
3、命令测试


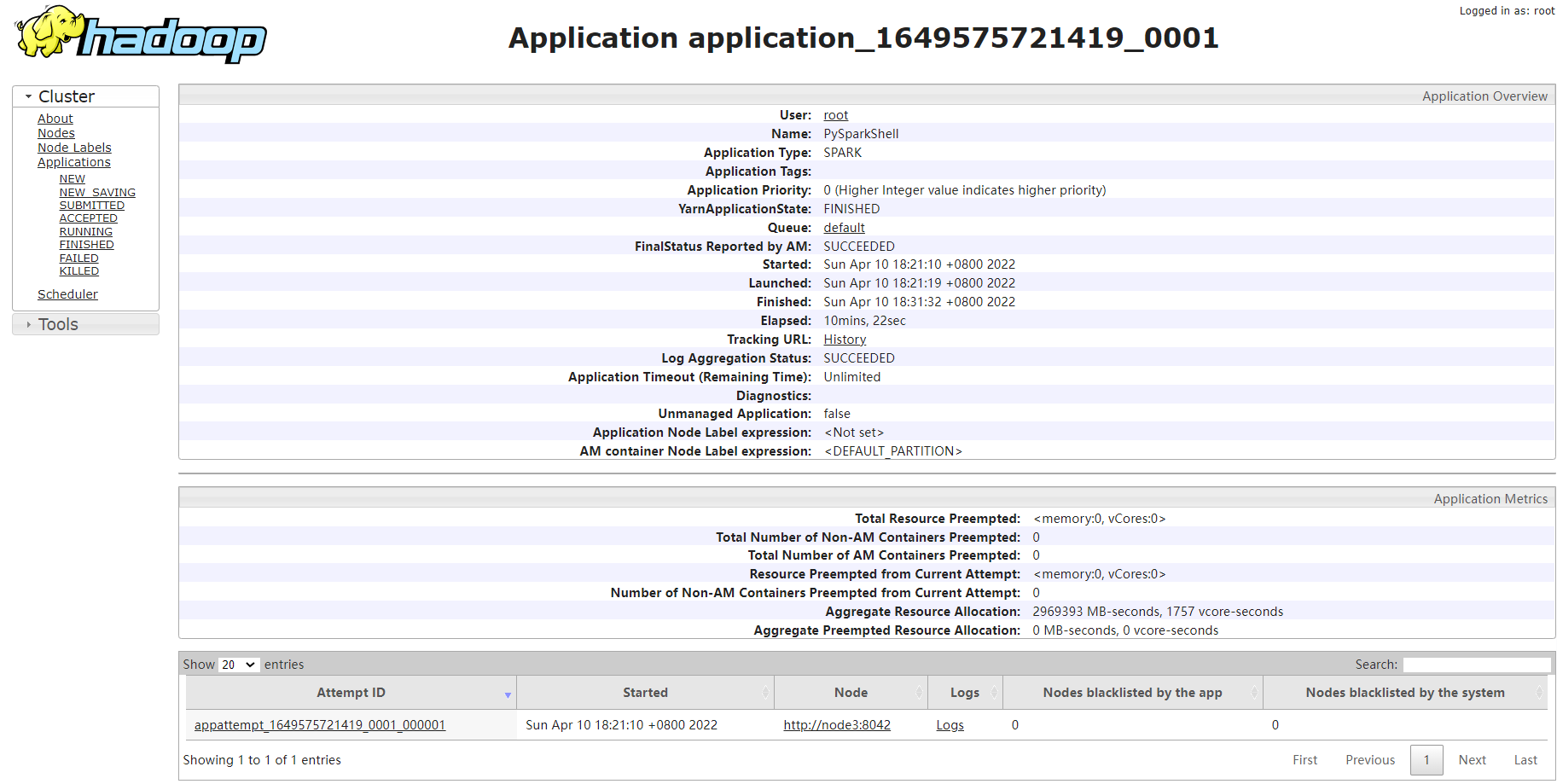
4、提交任务测试


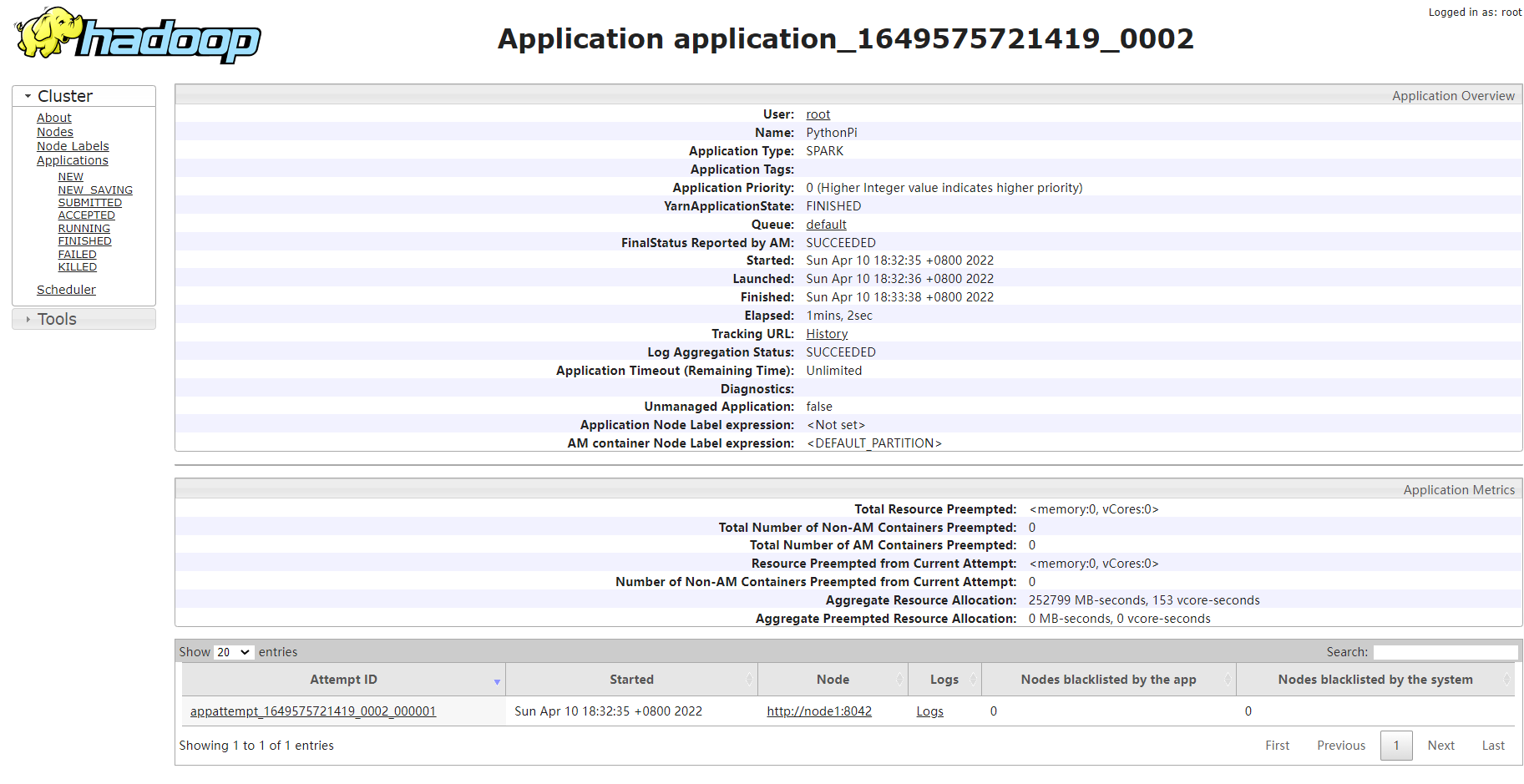
5、client模式测试pi



6、cluster模式测试pi